Signal vs. Noise
The Pure Neo AI Timeline provides you with all relevant AI news — without the hype.
Anthropic pilots Claude for Chrome with security safeguards
Anthropic has released a browser extension that integrates its Claude AI assistant directly into Google Chrome. The tool is in early testing with a limited group of users on the Claude Max plan. Alongside the launch, the company detailed new research on AI security threats and its measures to counter cybercriminal misuse.

Anthropic has begun piloting a Chrome extension that allows Claude to operate inside the browser environment. The extension gives users the ability to direct Claude to read pages, click through links, and complete web forms. The company said the pilot phase will involve 1,000 Max plan subscribers, with plans to expand after testing. This move brings Claude closer to being an active browser copilot, capable of supporting research, repetitive tasks, and structured workflows directly within Chrome.
Users remain in control of permissions. The extension requires site-level approval before Claude can act, and it asks for confirmation on sensitive operations such as form submissions. Certain high-risk categories of sites, such as financial services and government portals, are blocked outright. Anthropic described this as a necessary step to balance functionality with user protection.
Security testing has been a central part of the rollout. Anthropic evaluated how well Claude withstands prompt injection attacks designed to trick the model into unsafe actions. According to the company, the attack success rate dropped from 23.6 percent in earlier trials to 11.2 percent in current testing. On browser-specific attack types, Anthropic reported a reduction to zero. The company said this was achieved through additional layers of model training and guardrails built into the extension.
In parallel with the extension launch, Anthropic released its August 2025 Threat Intelligence report. The document details how malicious actors are attempting to misuse Claude for cybercrime. Case studies included attempts to generate extortion messages, create ransomware scripts, and support fraud schemes. Anthropic said its monitoring systems have been able to detect and block such misuse before it escalates.
The report emphasized that AI is lowering barriers for less-skilled attackers. Tasks that once required advanced technical ability, such as coding ransomware or writing convincing phishing campaigns, can now be attempted with model assistance. Anthropic argued that publishing data on misuse trends is necessary to maintain transparency and allow the wider security community to prepare countermeasures.
For enterprises, the extension and the security report point to two intersecting trends. On one side, AI is becoming a hands-on assistant capable of executing tasks across digital workflows. On the other, the same technology requires rigorous safeguards to prevent misuse. The company framed its dual announcement as a commitment to both expanding AI’s practical utility and addressing its risks.
Anthropic said it plans to expand access to Claude for Chrome after refining its security measures during the pilot phase. The extension could mark a shift in how AI assistants are embedded into everyday tools. At the same time, its simultaneous release of a security assessment underscores that adoption cannot be separated from the ongoing work of managing AI misuse.
Pure Neo Signal:
Microsoft releases VibeVoice-1.5B open-source long-form TTS model
Microsoft has released VibeVoice-1.5B, an open-source text-to-speech model capable of generating up to 90 minutes of continuous audio. The model can synthesize expressive conversations with up to four distinct speakers and is available under the MIT license with safeguards for responsible use.
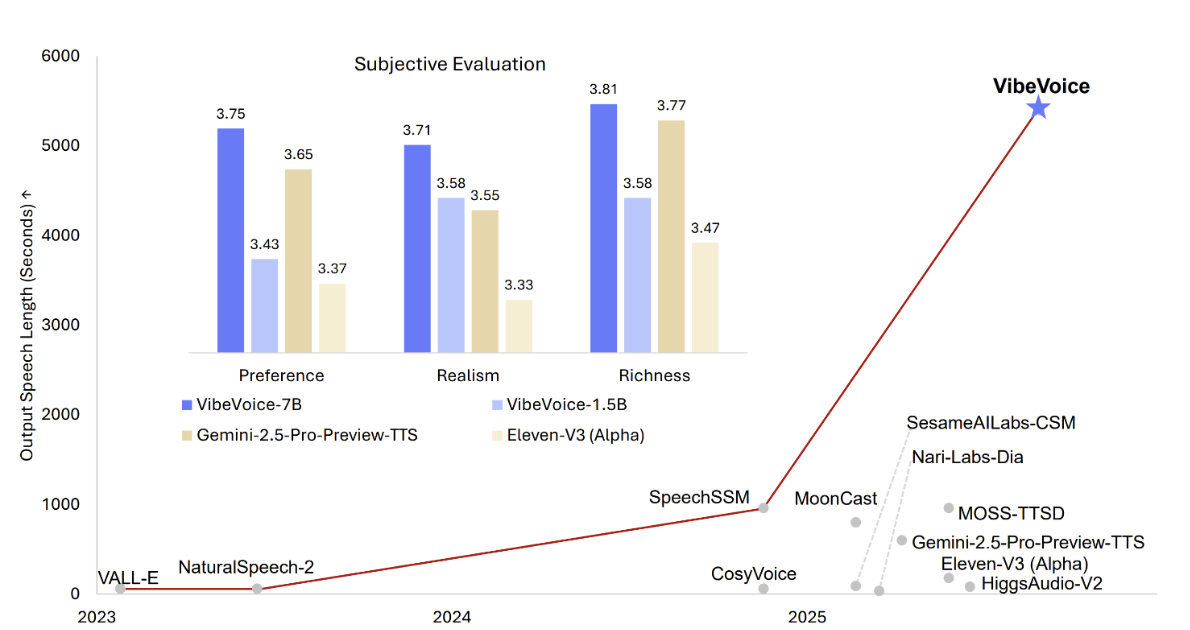
Microsoft’s new release, VibeVoice-1.5B, introduces long-form text-to-speech generation with multi-speaker support. The model can generate expressive dialogue involving multiple speakers, making it suitable for podcasts, audiobooks, and simulated conversations. Microsoft designed it to handle up to 90 minutes of uninterrupted speech, a benchmark that expands potential use cases for synthetic audio content.
The model is built on a 1.5-billion-parameter Qwen2.5-1.5B backbone and uses continuous speech tokenizers operating at 7.5 Hz. It employs a next-token diffusion framework that enables smooth and natural speech generation across extended durations.
To mitigate misuse, VibeVoice-1.5B integrates watermarking and audible disclaimers into generated audio. Microsoft released the model under the MIT license for research use, which allows broad experimentation while maintaining safeguards. The release includes documentation and examples that highlight applications in conversational AI and content production.
Alongside the release, Microsoft previewed a larger VibeVoice-7B model. Early benchmarks suggest that the 7B version delivers higher speech quality and more natural prosody compared to the 1.5B model. However, the trade-off is shorter output duration, with conversations limited relative to the extended 90-minute capability of the smaller model. This signals a possible product tiering where developers may choose between long-form generation at scale or higher-fidelity synthesis for shorter audio tasks.
VibeVoice-1.5B will be relevant to developers, AI audio researchers, and builders of no-code TTS applications. By making long-form, multi-speaker synthesis accessible in an open-source format, Microsoft positions the model as both a research tool and a foundation for applied audio workflows.
Pure Neo Signal:
Google debuts Gemini Nano-Banana image editing with lower cost than OpenAI
Google has upgraded its Gemini image editing model, now named Gemini 2.5 Flash Image. The model improves likeness preservation and consistency across edits while undercutting OpenAI’s average image generation cost. Pricing positions Gemini as a lower-cost option for developers and enterprises focused on high-volume content workflows.

Google has rolled out Gemini 2.5 Flash Image, formerly known as Nano-Banana, as its latest upgrade to Gemini’s image editing capabilities. The tool is available through the Gemini app, API, Google AI Studio, and Vertex AI. The model’s improvements focus on preserving likeness across edits, allowing consistent rendering of faces, backgrounds, and other features through multiple editing steps.
The upgrade also introduces multi-turn editing, style blending, and the ability to merge elements from several images. All generated images include visible watermarks and SynthID metadata to signal AI origin. Google positioned the model as a resource for developers and enterprises seeking scalable AI-driven editing tools that maintain fidelity across workflows.
Pricing comes in at around four cents per image, based on developer API usage. That compares with an average of nine cents per image for OpenAI’s gpt-image-1 model, which ranges between two and nineteen cents depending on output quality. The lower cost makes Gemini a competitive choice for businesses requiring large volumes of consistent edits, including e-commerce and marketing teams.
The release signals Google’s intent to expand adoption of its Gemini suite by combining lower cost with editing reliability. By focusing on character consistency and multi-step workflows, Google is positioning Gemini as a practical option in a market where price and stability directly influence deployment at scale.
Pure Neo Signal:
The internet is having a moment with Gemini’s new Nano-Banana editor. Early reactions show that people are struck not just by the price point but by how consistent the edits look. Character likeness, background fidelity, even pet photos — this is exactly the kind of detail that makes image generation tools useful instead of gimmicky. The reaction is fueling adoption at a pace that OpenAI and others will have to answer for.
Meanwhile, Adobe is facing uncomfortable questions. Stock contributors are noticing a drop in relevance as businesses explore Gemini and OpenAI as faster, cheaper ways to generate visuals. For a company that positioned itself as the professional’s platform, seeing internet users — including designers — praise Gemini’s editing workflows highlights how expertise in this field is shifting. If the tools are good enough for pros and cheap enough for scale, that spells a structural problem for Adobe’s creative ecosystem.
The takeaway is that Google has inserted itself squarely into the professional design conversation, not as a novelty but as an alternative workflow. And if Adobe cannot defend its stock marketplace with speed, pricing, or rights clarity, the internet’s current enthusiasm for Gemini might not just be a trend — it could be a signal that a long-standing industry model is weakening.
We love
and you too
If you like what we do, please share it on your social media and feel free to buy us a coffee.
xAI open-sources Grok 2 model on Hugging Face
Elon Musk’s AI company xAI has released Grok 2 as open source on Hugging Face. The model, with an estimated 270 billion parameters, comes under a custom license that permits commercial use but restricts model training. Musk confirmed plans to release Grok 3 in the coming months and reiterated xAI’s target of scaling compute to 50 million H100-equivalent GPUs within five years.
xAI has made its Grok 2 model openly available, describing it as the company’s top-performing system from last year. The release was confirmed by Elon Musk on X, who said the model would serve as a foundation for wider research and development. The announcement also included a commitment to release Grok 3 as open source within about six months.
Grok 2 is reported to have 270 billion parameters, designed as a mixture-of-experts model. In practice, only about 115 billion parameters are activated for each inference pass, with two out of eight expert modules engaged at a time. The model weights, split across 42 files and totaling around 500 gigabytes, are now hosted on Hugging Face.
The release comes with a new “Grok 2 Community License Agreement.” The license allows both commercial and non-commercial use of the model while barring its use for training or improving other AI systems. This structure gives developers freedom to deploy the model in production settings while maintaining guardrails around competitive reuse.
xAI’s move contrasts with the closed distribution of large models from competitors such as OpenAI. By placing Grok 2.5 in the open, the company offers researchers, startups, and enterprises direct access to a system at scale. The decision could accelerate experimentation in areas ranging from enterprise automation to consumer applications.
Alongside the release, Musk restated xAI’s long-term infrastructure goal. The company is targeting compute capacity equivalent to 50 million Nvidia H100 GPUs over the next five years. This ambition underscores the increasing competition among AI companies to secure hardware at scale and signals a strategy to support even larger models in the future.
Pure Neo Signal:
ByteDance releases Seed-OSS-36B with 512K token context
ByteDance has released Seed-OSS-36B, an open-source large language model with a native context length of 512,000 tokens. The model achieves leading open-source results in math, reasoning, and coding tasks while also supporting efficient deployment through quantization.
ByteDance’s Seed Team published the Seed-OSS-36B family under the Apache-2.0 license, making it available to developers and enterprises without usage restrictions. The models are trained to handle long documents natively, extending context support to half a million tokens. This capacity allows users to process entire books or large codebases without fine-tuning or external retrieval setups.
The instruct-tuned version, Seed-OSS-36B-Instruct, scores at the top of open-source leaderboards for reasoning, math, and code benchmarks. According to ByteDance, it also performs competitively on general natural language understanding while maintaining efficiency in long-context scenarios.
Deployment options include 4-bit and 8-bit quantization supported by Hugging Face Transformers and vLLM. These features are aimed at reducing memory requirements and making the model accessible for a wider range of production environments.
The release positions ByteDance as a major contributor to the open-source LLM ecosystem. For researchers, it offers a high-capacity model for experiments in reasoning and long-context workflows. For enterprises, it reduces infrastructure hurdles while extending the scope of AI applications such as document analysis, legal review, and large-scale code reasoning.
Pure Neo Signal:
DeepSeek releases V3.1 with 685B parameters and 128k context window
DeepSeek has launched its latest open-source AI model, DeepSeek-V3.1-Base, which comes with 685 billion parameters and a 128 000-token context length. The model posts benchmark results close to leading proprietary systems and is freely available for download, marking a significant move in the open-source AI landscape.
DeepSeek has unveiled DeepSeek-V3.1-Base, its newest large language model built with approximately 685 billion parameters. The release adds a 128 000-token context window and multi-format tensor support, including BF16, F8_E4M3, and F32. The model is distributed on Hugging Face in safetensors format, though no inference provider has yet integrated it.
Early benchmark data positions DeepSeek-V3.1 near the performance of leading proprietary models. The system scored 71.6 percent on the Aider coding benchmark, slightly higher than Anthropic’s Claude Opus 4. DeepSeek emphasized that the model achieves these results at lower projected costs compared with closed-source alternatives.
The release continues DeepSeek’s strategy of open sourcing frontier models. By making such a large-scale system available for public use, the company positions itself as a challenger to US-based firms that tightly control access to high-end AI systems. Developers and enterprises can download the model weights directly, enabling on-premise experimentation and deployment.
The model is expected to appeal to researchers, startups, and companies seeking to train or fine-tune systems without vendor lock-in. Its high parameter count and large context window could benefit tasks requiring reasoning across extended documents, coding projects, and multi-turn conversations. Analysts note that accessibility and cost advantages may increase adoption among organizations that have not engaged with closed-source alternatives.
Pure Neo Signal:
Alibaba releases Qwen-Image-Edit, an open-source foundation model for image editing
Alibaba’s Qwen team has released Qwen-Image-Edit, a 20-billion-parameter foundation model for text-driven image editing. The model supports both semantic and appearance-level modifications, including precise bilingual text editing, and is licensed under Apache-2.0 for commercial use.

Alibaba’s Qwen team has introduced Qwen-Image-Edit on Hugging Face as an open-source image editing foundation model. Built on the Qwen-Image architecture, it allows both high-level semantic edits, such as object manipulation and style transfer, and low-level appearance adjustments, including adding or removing elements with minimal disruption to surrounding content.
A key feature is its ability to modify text within images in both English and Chinese while preserving font, size, and style. This makes it suitable for design and localization workflows where text fidelity is critical. The model demonstrates state-of-the-art benchmark performance across editing tasks and completes simple edits within seconds.
Qwen-Image-Edit is released under the Apache-2.0 license, making it available for both research and commercial applications. To address hardware requirements, the team has provided a compressed DFloat11 variant that reduces model size by one-third and enables use on a single 32 GB GPU, with the option of CPU offloading for smaller configurations.
Deployment options include running locally on high-memory GPUs or accessing the model through Alibaba Cloud’s Model Studio. The release gives developers and enterprises an open-source alternative to proprietary image editing tools, with flexibility for integration into creative, enterprise, and consumer-facing workflows.
Pure Neo Signal:
Google adds automatic memory and temporary chat controls to Gemini
Google has begun rolling out automatic memory in Gemini AI, allowing the assistant to remember details from past interactions by default. The update also introduces a “Temporary Chat” mode that does not store or use conversations for training and expires after 72 hours. The changes aim to balance personalization with stronger privacy controls.
Google is enabling automatic memory for Gemini 2.5 Pro in select markets, with availability expanding to Gemini 2.5 Flash. The feature stores information such as names, preferences and recurring topics to tailor responses across sessions. Users can view and manage this data under a new “Personal Context” section in settings, including the option to disable memory entirely.
The company is also launching “Temporary Chats” for one-off or sensitive conversations. These sessions remain isolated from the memory system, are excluded from model training and automatically expire after three days. This option is available alongside existing chat history controls.
In a related change, “Gemini Apps Activity” will be renamed “Keep Activity” starting 2 September. This update will also allow Google to sample file and photo uploads for quality improvements, with options for users to manage or delete stored activity.
Google says the rollout will prioritize transparency and user control, with prompts informing users when information is being stored or when a chat is temporary. The combination of personalization and enhanced privacy tools positions Gemini to better compete with AI assistants that already offer similar capabilities.
Pure Neo Signal:
Comment
This week, Anthropic’s Claude and Google’s Gemini finally delivered memory features that track past conversations. ChatGPT introduced a similar ability only a few weeks earlier. It is progress, but what matters is what you can actually do with that memory.
OpenAI’s GPT-5 launch delivered horsepower, long context windows, routed reasoning, safety improvements, and versatile coding. It is not showing off much in terms of real-world workflows. In contrast, Anthropic and Google are wrapping practical tools around their models. Claude does not just remember. It is backed by Claude Code, an agentic assistant that lives in your terminal, understands your whole codebase, manages multi-file edits, runs tests, and acts autonomously. Google’s NotebookLM weaves AI into the research process, letting you ask questions of your documents, summarize dense material, and create AI-generated podcasts or featured learning notebooks.
Here is the rub. GPT-5 shows promise and power. But Claude and Gemini offer tangible tools you can use today, whether you are coding, researching, or organizing information.
We are entering an era where utility trumps hype. OpenAI may have the brain. Anthropic and Google are building the ecosystems. And right now, ecosystems get work done.
Google tests Magic View in NotebookLM as potential new data visualization feature
Google is trialing a new experimental feature in NotebookLM called Magic View. The tool displays an animated, dynamic canvas when activated, resembling a generative simulation. While the exact function is unconfirmed, early indications suggest it could provide new ways to visualize and interact with notebook content. The development follows recent updates to NotebookLM that expand multimedia support, including video overviews and mind maps.
Google has begun testing Magic View within NotebookLM for select users. Early testers describe it as an animated interface that responds dynamically to activation, although its precise capabilities have not yet been detailed by the company. The feature’s visual style has been compared to Conway’s Game of Life, a simulation often used to illustrate emergent patterns.
The introduction of Magic View aligns with a broader expansion of NotebookLM into multimedia and interactive content. In recent weeks, Google added tools for generating video overviews from notes and building mind maps automatically. These updates are aimed at making the platform more useful for collaborative research, project planning, and teaching.
If launched widely, Magic View could give students, educators, and researchers new ways to explore large bodies of information. Visual, interactive representations can help uncover patterns or relationships in data that are harder to see in text form. The feature would also strengthen Google’s position in the growing market for AI-assisted knowledge management platforms.
Google has not confirmed when Magic View might roll out to all users. Given its current testing status, the company is likely gathering feedback to refine both its function and its integration with other NotebookLM tools.
Pure Neo Signal:
Google releases Gemma 3 270M, an ultra-efficient open-source AI model for smartphones
Google DeepMind has released Gemma 3 270M, a compact 270 million-parameter model designed for instruction following and text structuring. The open-source model is optimized for low-power hardware, including smartphones, browsers, and single-board computers. Its efficiency enables AI capabilities in privacy-sensitive and resource-constrained environments.

Google DeepMind’s Gemma 3 270M targets developers building AI systems that run directly on devices without relying on cloud infrastructure. Quantized to INT4, the model powered 25 conversation turns on a Pixel 9 Pro using just 0.75 percent of battery. It offers pretrained and instruction-tuned versions, along with Quantization-Aware Training checkpoints for deployment in constrained environments.
The model achieves a 51.2 percent score on IFEval, outperforming similarly sized models and approaching the performance of larger billion-parameter models. Google has made model weights and deployment recipes available through platforms including Hugging Face, Vertex AI, llama.cpp, Gemma.cpp, and JAX.
Gemma 3 270M is aimed at enabling AI applications such as offline assistants, privacy-preserving chatbots, and embedded analytics tools. Its design supports rapid fine-tuning, making it viable for enterprise use cases requiring customization and compliance. The ability to run AI locally reduces network dependency, operational costs, and energy consumption while enabling continuous access in low-connectivity settings.
Google DeepMind stated that Gemma 3 270M represents a step toward specialized, efficient models as an alternative to scaling ever-larger AI architectures. This approach could make AI more accessible for developers and organizations that prioritize control, cost efficiency, and hardware independence.
Pure Neo Signal:
Claude adds memory search for past conversations
Anthropic has introduced a new memory feature in Claude that lets users search and reference past conversations in new chats. The feature launches today for Max, Team, and Enterprise plans, with availability for other plans expected soon. It aims to streamline workflows by eliminating repeated context-sharing and enabling project continuity.
Anthropic announced that Claude users on supported plans can now retrieve and reference earlier chat threads without leaving the current conversation. Once the feature is enabled in account settings under “Search and reference chats,” it can be toggled on or off at any time. This rollout is part of Anthropic’s efforts to make Claude a more effective long-term assistant.
Unlike some competitors, Claude’s new memory capability is not always active in the background. The system retrieves past conversations only when the user requests it, reducing passive data collection. This design allows for greater control over what information is carried forward between sessions.
The feature could benefit professionals who use Claude for research, project tracking, or ongoing collaboration. By recalling prior exchanges, Claude can resume a workflow without requiring the user to restate information. Anthropic noted that the capability will be expanded to more plans in the coming months.
Privacy controls remain central to the update. Users can review what conversations Claude references, and they can disable the function at any time through the settings menu.
Pure Neo Signal:
Anthropic expands Claude Sonnet 4 to 1 M token context
Anthropic has increased the context window for Claude Sonnet 4 to 1 million tokens, allowing the model to process entire codebases or dozens of research papers in a single prompt. The upgrade is available in public beta through Anthropic’s API and Amazon Bedrock, with Google Cloud Vertex AI integration planned. The change enables more coherent large-scale reasoning and workflow automation for developers and enterprises.
Anthropic’s latest update multiplies Claude Sonnet 4’s maximum context length by five, moving from 200,000 to 1 million tokens. This capacity allows users to input over 75,000 lines of code or a full collection of related research documents without splitting them into smaller parts. The company says the expansion reduces fragmentation and maintains more consistent reasoning across extended tasks.
The 1 million token context is currently available in public beta on Anthropic’s API at Tier 4 or via custom rate limits, as well as on Amazon Bedrock. Integration with Google Cloud Vertex AI is scheduled for release in the coming weeks. Anthropic has adjusted its pricing for prompts exceeding 200,000 tokens, while offering prompt caching and batch processing to manage cost and latency.
Early adopters include AI-first development platforms such as Bolt.new and iGent AI. Both report using the expanded context to execute full engineering workflows, including multi-day coding sessions and project-wide refactoring, without intermediate handoffs. For research teams, the new limit enables full-document ingestion and multi-source synthesis in one pass.
The move follows a broader industry trend of expanding model context to support agent-based systems and complex autonomous workflows. By reducing the need for manual context management, Anthropic aims to make Claude more effective for enterprise-scale deployment.
Pure Neo Signal:
Google makes Jules, its AI coding agent, generally available
Google has transitioned Jules from Google Labs beta to full public release. Powered by Gemini 2.5 Pro, Jules runs asynchronously in a cloud VM to read, test, improve, and visualize code with minimal developer oversight. The launch adds a free tier alongside paid “Pro” and “Ultra” plans and introduces a critic capability that flags issues before changes are submitted.
Google debuted Jules in December 2024 as an experimental agent within Google Labs, later opening it to public beta in May 2025. Following months of beta testing that generated thousands of tasks and more than 140,000 code improvements, the company has now promoted Jules to general availability. The update includes a redesigned interface, bug fixes, GitHub Issues integration, and multimodal output support.
Jules runs in a secure Google Cloud virtual machine, cloning a user’s repository and performing tasks such as writing tests, fixing bugs, updating dependencies, and summarizing changes with audio changelogs. Its asynchronous design allows developers to start tasks and continue other work without monitoring execution in real time.
Pricing is structured into three tiers: a free tier with 15 tasks per day and three concurrent jobs, a Pro tier with roughly five times those limits, and an Ultra tier with up to twenty times the capacity. All tiers use Gemini 2.5 Pro.
The critic-augmented generation feature reviews Jules’s proposed changes before submission and flags issues from logic errors to inefficiencies, allowing the agent to replan or revise before completing the task. Google positions Jules as part of its broader strategy to embed task-oriented AI agents into everyday workflows across technical and non-technical domains.
Pure Neo Signal:
OpenAI Publishes GPT-5 Prompting Guide and Releases Prompt Optimizer Tool
OpenAI has added a GPT-5 prompting guide to its public Cookbook and launched a Prompt Optimizer in the Playground. The resources are designed to improve the quality, efficiency, and consistency of prompts for the new model, with specific guidance for agentic tasks, coding workflows, and instruction adherence.
OpenAI’s updated Cookbook now includes a GPT-5 prompting guide that outlines strategies for building high-performing prompts. The guide covers steerability, verbosity control, agentic workflows, and prompt migration. It includes code samples and workflow diagrams aimed at helping developers adapt to GPT-5’s expanded reasoning capabilities.
The company has also introduced a Prompt Optimizer in the Playground interface. The tool analyzes user prompts and generates optimized versions. It can identify inefficiencies, improve clarity, and help with migrating GPT-4 prompts to GPT-5. Developers can review suggestions side-by-side with their original prompts, with support for saving reusable prompt objects.
According to OpenAI, the Prompt Optimizer supports both manual and automated refinements. Early usage examples in the Cookbook show measurable gains in model adherence to instructions and reduced token usage without sacrificing quality.
The new guide and tool aim to standardize best practices for GPT-5 prompt engineering. This is expected to reduce trial-and-error in production environments and accelerate deployment for agentic systems, code generation, and structured output workflows.
Pure Neo Signal:
OpenAI launches GPT-5 with unified fast and reasoning modes for API and ChatGPT
OpenAI has released GPT-5, a flagship language model combining high-speed responses with advanced reasoning in a single system. The model is available immediately in the OpenAI API and to ChatGPT Team users, with Enterprise and Education accounts gaining access next week. GPT-5 introduces a 400,000-token context window, enhanced coding performance, expanded developer controls, and improved reliability over previous models.

OpenAI describes GPT-5 as a routed system that integrates two distinct capabilities: a fast model for quick answers and a deep reasoning model for complex, multi-step tasks. An internal router, trained on usage signals, decides which mode to use based on the prompt’s complexity. This enables faster turnaround for straightforward queries while deploying deliberate reasoning for analytical or technical requests. Developers have the option to override routing through new API settings such as reasoning: "minimal" and verbosity, giving them more control over response depth and length.
The expanded 400,000-token context window is a key technical upgrade. This capacity allows GPT-5 to process extensive materials — large codebases, multi-document legal reviews, or book-length manuscripts — in a single prompt. Tasks that previously required splitting content into smaller segments can now be executed without context fragmentation, improving both accuracy and efficiency.
Benchmarking data in OpenAI’s GPT-5 System Card shows measurable gains. GPT-5 is 45% less likely to hallucinate than GPT-4o, and 80% less likely than OpenAI’s o3 reasoning model. Coding tests demonstrate state-of-the-art performance: 74.9% on SWE-bench Verified and 88% on Aider Polyglot, reflecting higher accuracy in code generation and bug fixes. Tool usage has also been refined, with the model better able to call APIs, integrate data, and generate complete front-end interfaces from specifications.
Pure Neo Signal:
GPT‑OSS: OpenAI Publishes 20B and 120B Open‑Weight Models for Local Deployment
OpenAI has released gpt‑oss‑120b and gpt‑oss‑20b, its first open‑weight models since GPT‑2. The models match or exceed the performance of proprietary counterparts and mark a rare moment of open source leadership from a U.S.-based AI lab. With support for tool use, chain‑of‑thought reasoning, and smooth MacBook deployment, gpt‑oss is designed for full local control.
OpenAI has launched two new open-weight models—gpt‑oss‑120b and gpt‑oss‑20b—under an Apache 2.0 license. The move breaks a five-year drought in U.S. open releases at this level of scale and quality. Both models can be fine-tuned and deployed locally or via major platforms including Hugging Face, AWS, Azure, and Databricks. The 120b model contains roughly 117 billion parameters (with 5.1 billion active) and runs on a single 80 GB H100 GPU. The smaller 20b variant fits in 16 GB of memory.
The release comes after weeks dominated by China's open-source leaders, including DeepSeek-VL, Qwen2, and Kimi 2.0. Until now, U.S. labs lagged in making high-quality open models available. With gpt‑oss, OpenAI re-enters the open-source scene by releasing a model that not only competes but in some areas outperforms the best available. It’s a notable shift in momentum in the global race for open AI infrastructure.
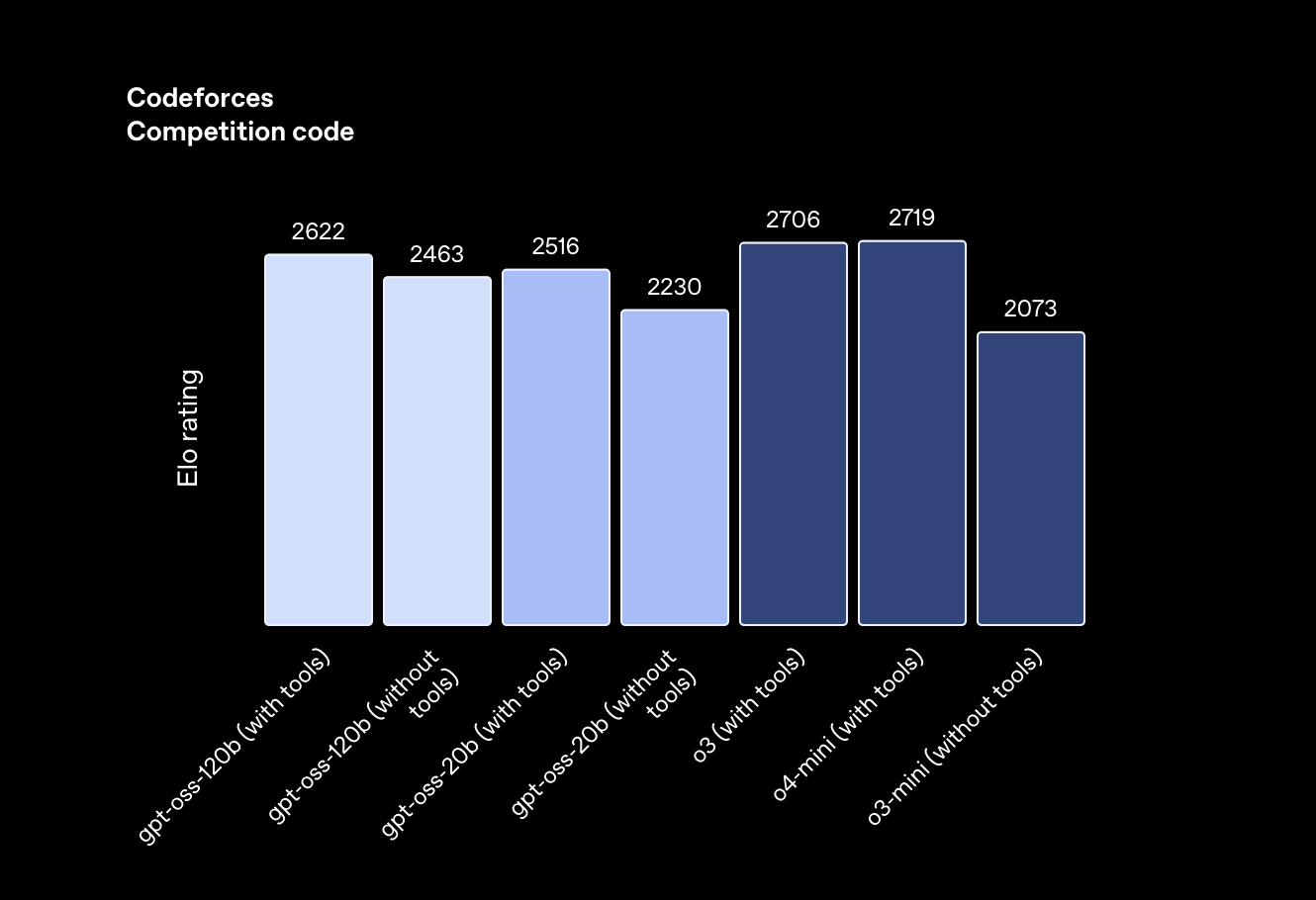
Benchmark results shared by OpenAI show that gpt‑oss‑120b outperforms o4‑mini, a proprietary model, on tasks like MMLU, Codeforces, and HealthBench. The 20b model also competes strongly, exceeding o3‑mini across several metrics. The models support agentic use cases, configurable reasoning effort, and chain-of-thought prompting, making them well-suited for developers building autonomous systems or local copilots.
For Apple users, there’s another reason to pay attention. MLX-optimized builds of both models are already available, enabling smooth inference on Apple Silicon Macs. The models run efficiently even on consumer MacBooks, making gpt‑oss a practical foundation for desktop-based LLM applications. This lowers the barrier for indie devs and researchers who want fine-grained control without relying on cloud APIs.
Unlike most closed-source commercial models, gpt‑oss is designed for modification. The full training recipe is not included, but OpenAI has published a detailed model card, parameter counts, architecture notes, and fine-tuning tools. Safety measures include evaluations by a third-party red-teaming vendor and red-teaming API interface, plus alignment via reinforcement learning and supervised fine-tuning.
OpenAI says the release is meant to support safety research, transparency, and broader access. It follows the launch of o4 in June and may reflect internal tension between OpenAI’s closed commercial roadmap and its original open science roots. By releasing performant open-weight models now, OpenAI also sets a benchmark that could pressure others—particularly Meta and Anthropic—to follow suit.
While not full end-to-end reproducibility, gpt‑oss offers what many researchers and startups have asked for: a U.S.-backed, high-performance model that can be studied, deployed, and adapted without license restrictions. It may not mark a total return to openness, but it’s a meaningful step toward rebuilding trust and enabling local AI development at scale.
Pure Neo Signal:
Claude Opus 4.1 Raises Coding and Reasoning Performance
Anthropic has released Claude Opus 4.1, a mid-cycle upgrade focused on coding accuracy, reasoning stability, and better multi-file task tracking. It delivers improved benchmark scores and enhanced real-world usability, particularly for enterprise and developer workflows. The update is live across Claude Pro, API, Bedrock, and Vertex AI with no pricing change.
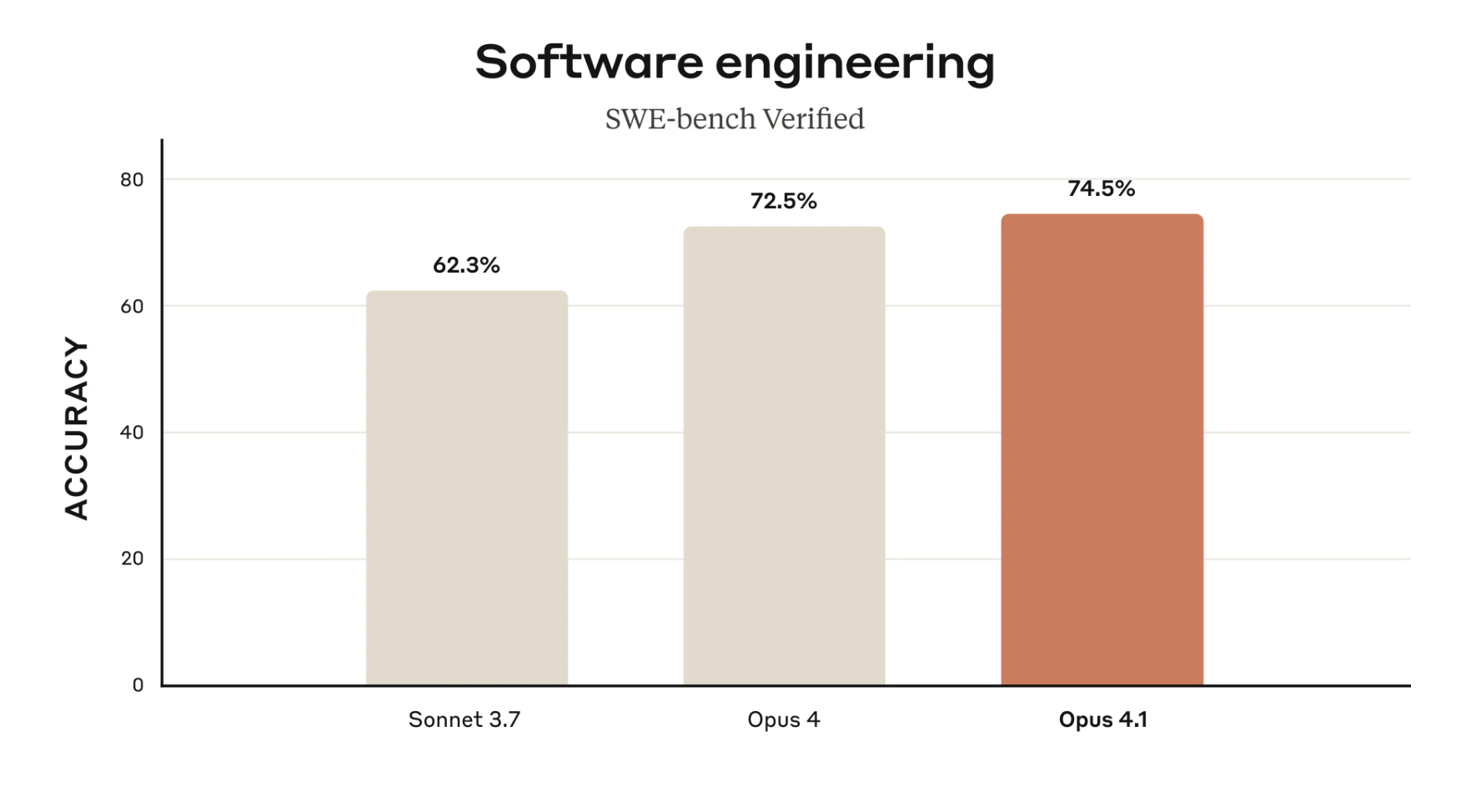
Claude Opus 4.1 builds on its predecessor with key improvements in detailed reasoning, agentic task handling, and software development. It scores 74.5% on SWE-bench Verified, up from Opus 4’s 72.5%, reflecting stronger multi-step problem-solving and reliability in complex scenarios. Anthropic highlights better performance in multi-file code refactoring, workflow memory, and research-heavy tasks like data analysis and summarization.
The release is intended as a drop-in upgrade. It requires no changes for existing API users and continues to serve as the most capable Claude model. While not a major architectural shift, it marks a steady refinement of Claude’s core capabilities for developers and enterprise teams building with large-context AI. Anthropic’s iterative model strategy suggests larger upgrades are ahead, but for now, 4.1 sharpens the edge without raising costs.
Pure Neo Signal:
DeepMind Debuts Genie 3 for Real-Time Text-to-3D World Generation
A new generation of world models is here. DeepMind’s Genie 3 turns text prompts into playable 3D environments at 24 fps with persistent memory and interactive elements. While still in research preview, it represents a major step toward AI agents that can learn and act in open-ended virtual worlds.

DeepMind has unveiled Genie 3, its most advanced world model to date. This system can transform a single text prompt into an interactive 3D simulation in real time, complete with coherent object placement, emergent memory, and dynamic events like changing weather. The output runs at 720p and 24 frames per second, pushing the boundaries of what generative AI can render and maintain over time.
The implications extend beyond graphics. Genie 3 supports embodied agents like DeepMind’s SIMA, allowing AI to train in synthetic environments with increasing realism. Developers can tweak scenes mid-simulation, enabling new research directions in continual learning and simulation-based reinforcement learning. For AI researchers, game developers, and virtual educators, it hints at a powerful future where simulations are not authored, but generated.
Though Genie 3 is not yet publicly released, its capabilities signal DeepMind's intent to dominate the world model space. With real-time generation, memory persistence, and interactive physics, Genie 3 edges closer to the kind of dynamic environments required for generalist AI systems.
Pure Neo Signal:
Alibaba Shrinks Its Coding AI to Run Locally
Qwen3-Coder-Flash is a compact, 30B MoE model capable of local inference on modern MacBooks. It joins Alibaba’s broader Qwen3 ecosystem as a nimble counterpart to the heavyweight 480B hosted version, giving developers a pragmatic hybrid setup for coding workflows.
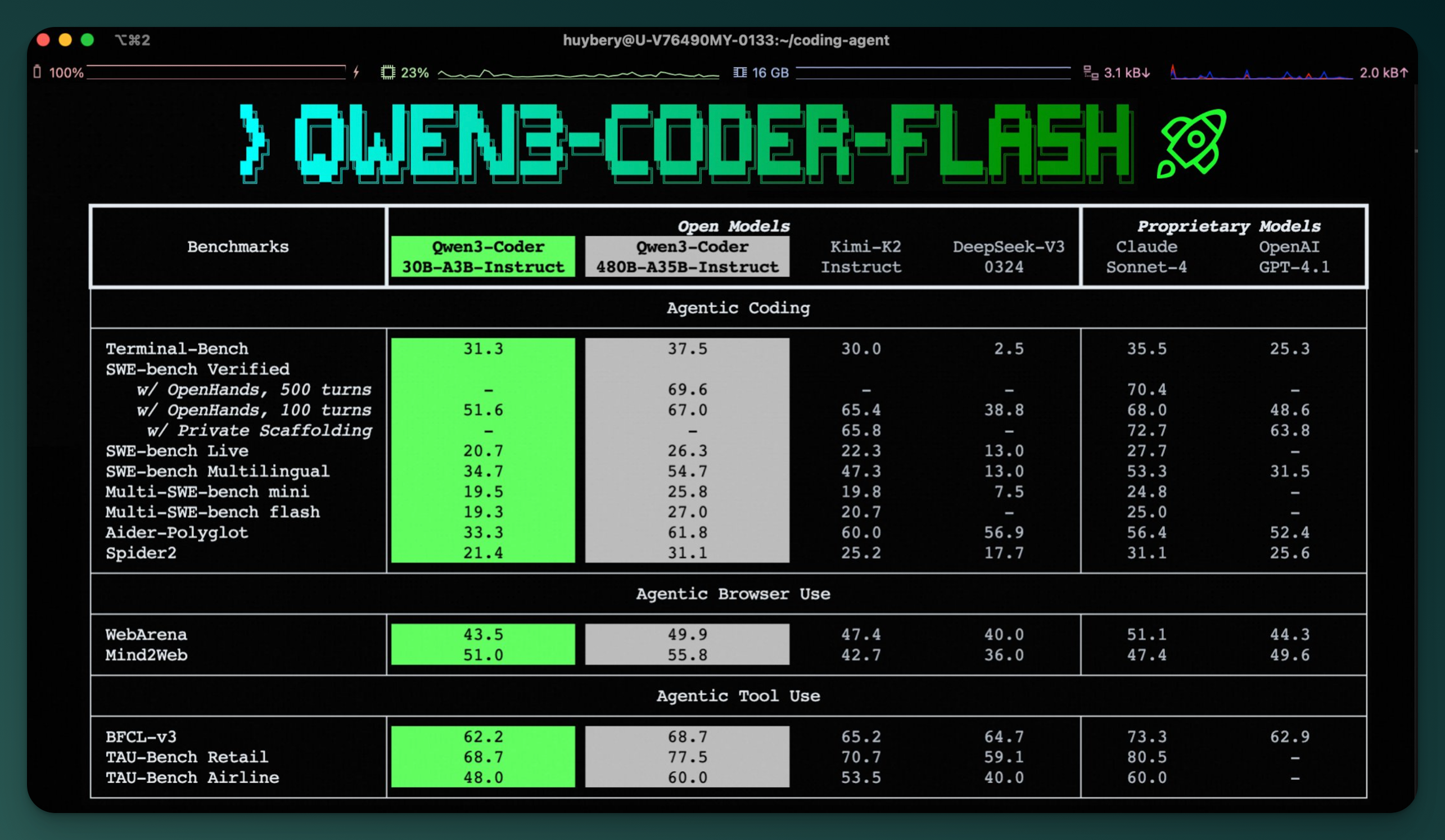
Alibaba’s Qwen team has released a scaled-down version of its coding AI, dubbed Qwen3-Coder-30B-A3B-Instruct or “Flash.” Unlike its 480B-parameter big brother, this model runs on consumer-grade hardware. With just 25 GB of unified memory, it can operate locally on a MacBook or modest workstation. The design uses a Mixture-of-Experts (MoE) architecture that activates only 3 billion parameters per token, making it resource-efficient while still supporting features like 256K context length and function-calling.
The release positions Flash as a lightweight agentic coding model for developers who want speed and privacy without sacrificing modern capabilities. For heavier workloads, users can still rely on the hosted Qwen3-Coder-480B-A35B model. That model handles advanced reasoning and massive token windows, but at the cost of requiring significant infrastructure. Together, the two create a hybrid usage pattern: run Flash locally for day-to-day tasks and call on the 480B model via API when scale or complexity demands it.
This move signals a trend toward tiered deployment strategies where developers pick the model size based on the job. Flash fits the growing appetite for capable, open-source LLMs that don’t depend on cloud GPUs or vendor lock-in. By bridging performance and portability, it gives indie devs and SMBs a viable alternative to always-online coding copilots.
Pure Neo Signal:
NVIDIA Releases Llama Nemotron Super v1.5 to Push Open-Source Agent Reasoning
The new 49B model tops open benchmarks with a 128K context window, tool-use capabilities, and single‑GPU efficiency. It's a signal that NVIDIA aims to lead in agent‑focused LLMs that actually run in production.
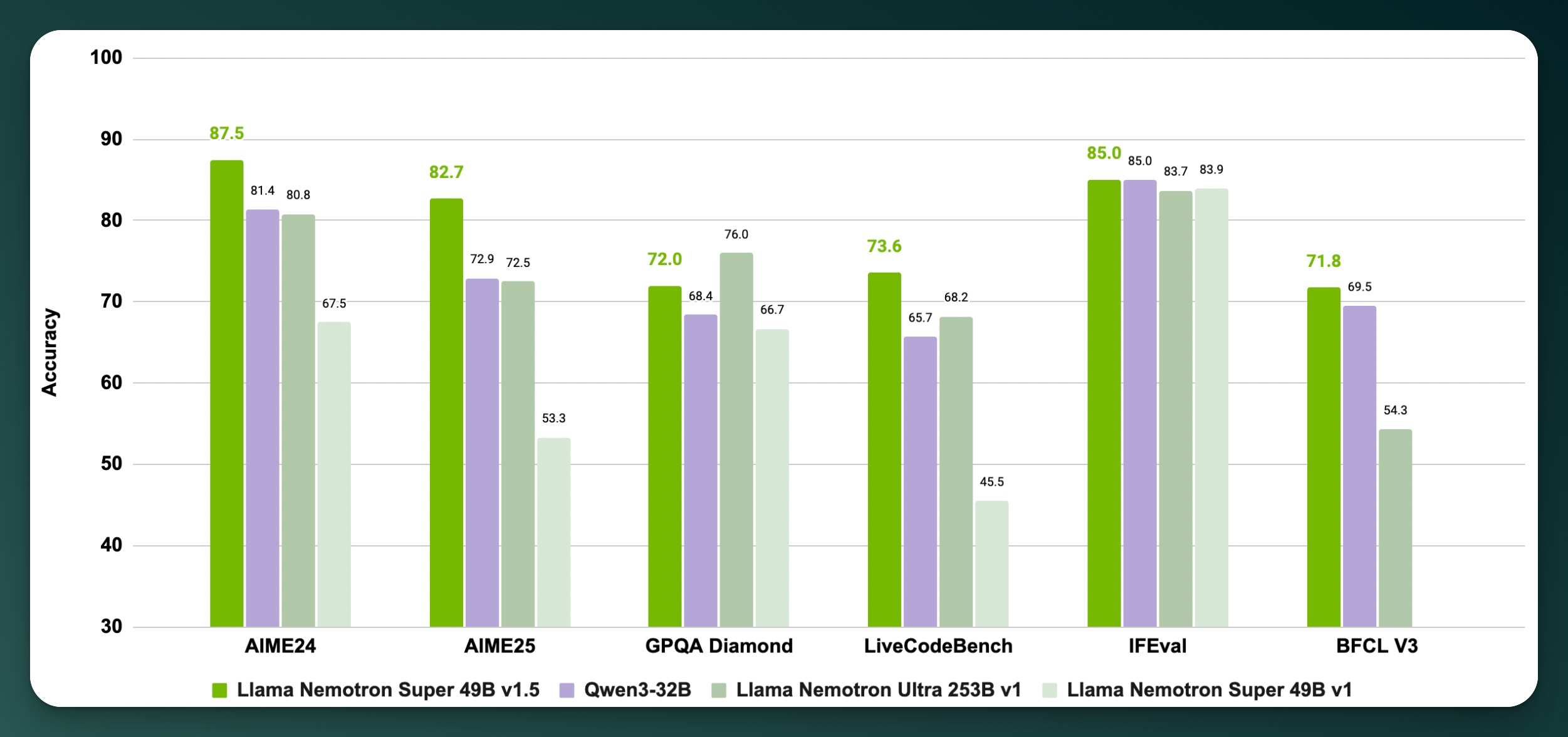
NVIDIA has released Llama‑3.3‑Nemotron‑Super 49B v1.5, an open-weight LLM designed to deliver top-tier reasoning, math, and tool-calling performance at a mid-size model scale. The model outperforms leading open competitors like Qwen3‑235B, DeepSeek R1‑671B, and even NVIDIA’s own prior Nemotron Ultra 253B across key reasoning benchmarks. Despite its smaller footprint, it features a 128K token context window and excels at multi-turn reasoning tasks.
What sets v1.5 apart is its combination of size and accessibility. It was built using neural architecture search (NAS) to optimize for H100/H200 GPUs, meaning it runs efficiently on a single high-end card. This lowers the barrier for developers building RAG agents, math solvers, and code assistants in real-world applications. Alongside the model, NVIDIA has released the full post-training dataset used for alignment and reasoning tuning, a move that enhances transparency and reproducibility in commercial deployments.
In a field increasingly dominated by massive, inaccessible models, NVIDIA is positioning Nemotron Super v1.5 as the pragmatic choice for agentic system developers. It's not just a benchmark leader. It's designed to work in actual production environments, with open weights, permissive licensing, and GPU efficiency that SMBs and startups can use today.
