Alibaba Shrinks Its Coding AI to Run Locally
Qwen3-Coder-Flash is a compact, 30B MoE model capable of local inference on modern MacBooks. It joins Alibaba’s broader Qwen3 ecosystem as a nimble counterpart to the heavyweight 480B hosted version, giving developers a pragmatic hybrid setup for coding workflows.
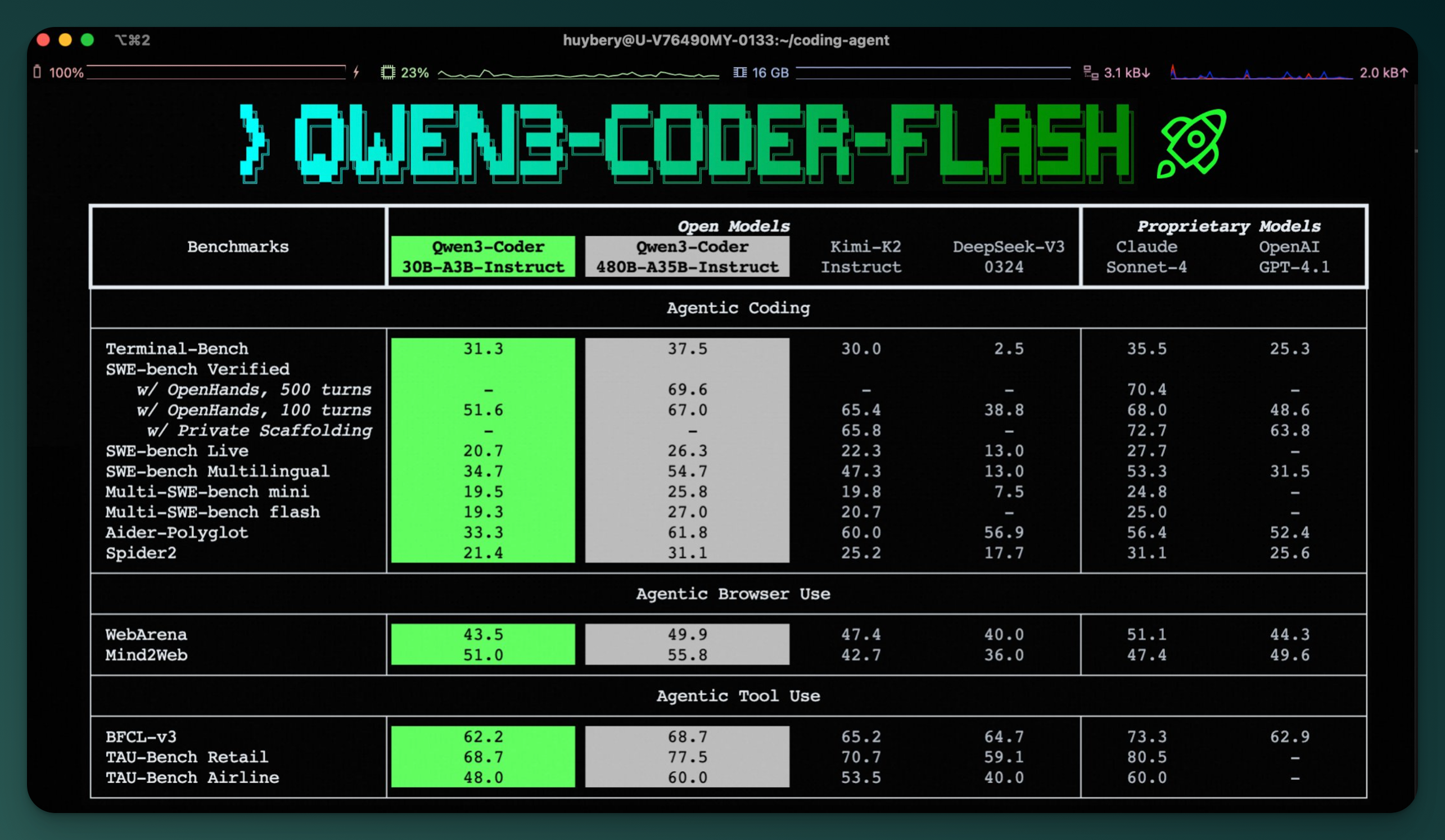

Alibaba’s Qwen team has released a scaled-down version of its coding AI, dubbed Qwen3-Coder-30B-A3B-Instruct or “Flash.” Unlike its 480B-parameter big brother, this model runs on consumer-grade hardware. With just 25 GB of unified memory, it can operate locally on a MacBook or modest workstation. The design uses a Mixture-of-Experts (MoE) architecture that activates only 3 billion parameters per token, making it resource-efficient while still supporting features like 256K context length and function-calling.
The release positions Flash as a lightweight agentic coding model for developers who want speed and privacy without sacrificing modern capabilities. For heavier workloads, users can still rely on the hosted Qwen3-Coder-480B-A35B model. That model handles advanced reasoning and massive token windows, but at the cost of requiring significant infrastructure. Together, the two create a hybrid usage pattern: run Flash locally for day-to-day tasks and call on the 480B model via API when scale or complexity demands it.
This move signals a trend toward tiered deployment strategies where developers pick the model size based on the job. Flash fits the growing appetite for capable, open-source LLMs that don’t depend on cloud GPUs or vendor lock-in. By bridging performance and portability, it gives indie devs and SMBs a viable alternative to always-online coding copilots.
Pure Neo Signal:
We love
and you too
If you like what we do, please share it on your social media and feel free to buy us a coffee.

