
November 9, 2025
OpenAI
ACP
PayPal Adopts OpenAI’s Agentic Commerce Protocol for ChatGPT Shopping
PayPal partners with OpenAI to bring direct shopping and payments to ChatGPT through the open source Agentic Commerce Protocol, establishing a framework for AI-native commerce and merchant participation across platforms.
PayPal has become the first large-scale adopter of OpenAI’s open source Agentic Commerce Protocol (ACP), a specification designed to standardize AI-driven shopping experiences. The partnership enables users to browse, select, and purchase products directly within ChatGPT, with transactions powered by PayPal’s infrastructure.
The integration builds on OpenAI’s “Instant Checkout” feature, introduced in September 2025, which allows users to confirm orders, shipping details, and payments within the chat interface. By connecting with ACP, PayPal will make its payment network available to both buyers and merchants participating in AI-native transactions. Users will be able to pay using their PayPal wallets for protection and dispute resolution, while a separate API will enable direct card payments.
Beginning in 2026, merchants using PayPal will have their product catalogues automatically discoverable through ChatGPT across multiple categories, including fashion, beauty, home improvement, and electronics. They will not need to perform additional integration steps, reducing friction for small and medium-sized sellers.
PayPal also plans to release an agentic commerce suite that allows merchants to showcase products in AI apps, accept payments across platforms, and access consumer insights generated by AI-driven interactions. “By partnering with OpenAI and adopting the Agentic Commerce Protocol, PayPal will power payments and commerce experiences that help people go from chat to checkout in just a few taps,” said Alex Chriss, President and CEO of PayPal.
The collaboration underscores a broader industry move toward open standards in AI commerce. Because ACP is open source, developers and merchants beyond OpenAI’s ecosystem can participate, potentially accelerating the adoption of interoperable AI shopping protocols across different platforms.
Data Source
November 9, 2025
SAP
SAP RPT-1
OpenSource
SAP debuts RPT-1, a foundation model (and open-source variant) for relational enterprise data
SAP introduces a new foundation model that applies in-context learning to structured business data. The model (including an open-source version) was revealed at SAP TechEd 2025 and broadens access to tabular-data AI.
SAP has unveiled SAP RPT-1, its first large-scale foundation model for relational business data. The model is designed to handle structured, table-based datasets common in enterprise systems. It uses in-context learning, allowing users to provide a few example rows of data and receive predictions for new entries without the need for traditional model retraining.
The company describes RPT-1 as a “table-native” transformer that understands the schema and semantics of relational data. SAP said the approach reduces the complexity of building and maintaining multiple machine-learning models across business domains such as finance, supply chain and customer operations. By leveraging contextual examples rather than task-specific fine-tuning, RPT-1 aims to make predictive AI accessible to both business users and data scientists.
Notably, the RPT-1 family includes two commercial builds and an open-source variant named sap-rpt-1-oss, licensed under Apache-2.0 and available via GitHub and Hugging Face. The open variant is intended for research and community use, lowering the barrier for experimentation and innovation with enterprise-style tabular AI.
The announcement was made during SAP TechEd 2025 in Berlin. Analysts note that the open-source release expands the potential ecosystem beyond SAP’s own cloud services, making it relevant to developers, no-code tools and universities as well as enterprise buyers.
For enterprises running SAP’s ERP and analytics systems, RPT-1 could reduce the cost and time required to operationalise AI. The open-source variant could also enable smaller companies and academic teams to test and prototype tabular-AI use-cases without vendor lock-in.
While the concept aligns with industry efforts to extend foundation models beyond text and images into structured data, SAP emphasises that the model still depends on data quality, domain alignment and appropriate deployment practices. The open-source edition invites the community to validate, extend and integrate the model into broader toolchains.
Data Source
November 9, 2025
Gradient
Parallax
Gradient Network launches Parallax, a decentralized inference engine for AI models
Parallax introduces a distributed approach to large language model inference, enabling global collaboration and decentralized compute across heterogeneous devices. Gradient Network positions it as the foundation for a new open, community-driven AI infrastructure.
Gradient Network has unveiled Parallax, a fully distributed inference engine designed to transform how large language models (LLMs) are served and scaled. The system reimagines inference as a global, collaborative process in which models are executed across a mesh of interconnected devices rather than centralized data centers.
Parallax aims to address the growing demand for compute power as AI models expand in size and complexity. By distributing inference tasks among consumer GPUs, Apple Silicon systems, and other edge devices, Parallax reduces reliance on enterprise-grade infrastructure. The company says this approach improves scalability, sovereignty, and cost-effectiveness while lowering barriers to entry for developers and organizations.
The platform introduces three core shifts: intelligence sovereignty, which allows individuals to run advanced models locally without centralized control; composable collaborative inference, enabling shared execution across multiple machines; and latent compute utilization, which turns idle devices into active nodes in a global serving network.
Architecturally, Parallax combines NVIDIA GPU and Apple Silicon support within a unified serving runtime. It employs continuous batching and paged key–value cache management to maximize throughput and concurrency. The system’s communication layer relies on peer-to-peer tensor streaming via a decentralized hash table, while a worker layer coordinates heterogeneous compute through a dual-platform design based on SGLang and a custom MLX-compatible runtime.
In benchmarks against the Petals distributed inference framework, Parallax achieved up to 5.3× lower inter-token latency and 3.1× improvements in overall throughput using the Qwen2.5-72B-Instruct-GPTQ-Int4 model. Performance remained stable across varying input lengths and batch sizes, suggesting scalability potential for real-world workloads.
The company also launched a closed beta chatbot powered by Parallax to demonstrate real-time decentralized inference. Each response is generated by a swarm of participating nodes rather than a centralized server. Gradient Network plans to open-source Parallax after production readiness, integrating it with its existing Lattica communication layer to form what it calls a “fully open, decentralized AI stack.”
Data Source
November 9, 2025
Docker
MCP
Docker launches MCP Toolkit to connect Claude Desktop with containerised servers
Docker’s new MCP Toolkit allows developers to run Model Context Protocol (MCP) servers in secure containers and link them directly to Claude Desktop. The launch enables AI assistants like Claude to perform real-world tasks through controlled, reproducible environments that integrate with developer tools and APIs.
Docker has released the MCP Toolkit, a set of utilities that connect containerised MCP servers to Claude Desktop. The integration bridges conversational AI models and developer workflows by allowing AI to execute actions within isolated Docker containers. It expands Docker’s developer ecosystem into AI-driven productivity.
The MCP Toolkit provides a catalogue of ready-to-use servers, including GitHub, Firecrawl, Node.js Sandbox, Sequential Thinking, and Context7. Each runs in its own Docker container, maintaining system security while allowing the AI to interact with APIs, files, or development environments. Docker demonstrates workflows such as generating a React component from a UI screenshot, testing it locally, and committing it to a GitHub repository — all through Claude Desktop.
Docker positions the MCP Toolkit as a step toward safer AI automation. By using containers, developers can restrict what the AI can access, ensure reproducibility, and prevent unsafe code execution. This approach allows Claude to move from being a reasoning agent to a trusted actor that operates within well-defined technical boundaries.
The release follows growing interest in connecting large language models to secure runtime environments. Docker’s strategy combines its core strength in container orchestration with AI agent infrastructure, appealing to developers and AI tool builders seeking to bridge reasoning and execution layers.
Data Source
November 6, 2025
Gemini
Google DeepMind Launches File Search Tool for Gemini API
The new File Search Tool adds a fully managed retrieval-augmented generation (RAG) system directly into the Gemini API, giving developers an integrated and scalable way to ground responses in their own data without building a custom retrieval pipeline.
Google DeepMind has introduced the File Search Tool, a managed RAG solution built into the Gemini API that simplifies how developers connect their data to Gemini models. The system automates key retrieval tasks such as file storage, chunking, embedding generation, and context injection, allowing teams to focus on application logic rather than data infrastructure.
The File Search Tool uses Google’s latest Gemini Embedding model to perform vector searches that capture the meaning of queries, not just their keywords. Responses include built-in citations linking back to source documents, improving transparency and traceability. Developers can use a broad set of supported file formats including PDF, DOCX, TXT, JSON, and many programming language file types.
Google has introduced a cost model designed to make RAG development more accessible. Embedding generation at query time and file storage are free, while initial embedding creation is priced at $0.15 per million tokens. The approach reduces ongoing costs and simplifies scaling for both small and enterprise deployments.
Early adopters have reported strong performance results. Phaser Studio’s Beam platform, which builds AI-driven games, uses File Search to query thousands of documents daily across multiple corpora. The company says search operations now complete in under two seconds, replacing manual cross-referencing that previously took hours.
Developers can start using the File Search Tool immediately through the Gemini API and Google AI Studio, where a demo app showcases practical implementations for knowledge assistants, support bots, and creative discovery systems.
Data Source
November 5, 2025
Gemini
Google expands Gemini Deep Research to Gmail, Drive, and Chat
The AI assistant can now pull insights from emails, documents, and internal chats, combining them with live web data for personalized research.
Google has expanded its Gemini Deep Research tool to access data across Gmail, Google Drive, and Google Chat. The integration allows users to generate tailored research reports using both internal Workspace data and web sources. The feature is live on desktop and will reach mobile users in the coming days.
Gemini Deep Research is part of Google’s effort to make its AI assistant more context-aware. Users can now specify which sources the AI should analyze, selecting from web results, email threads, shared files, and chat histories. The system then compiles the information into concise summaries or reports, making it suitable for professional use cases such as project tracking, competitor research, or client briefings.
According to Google, all Workspace data used by Deep Research remains private and compliant with organizational data settings. The AI model processes user content temporarily to generate responses without storing or reusing the information for training.
The update positions Gemini more directly against Microsoft’s Copilot for Microsoft 365, which already integrates with Outlook, Teams, and Office documents. By bringing Workspace data into Gemini’s research workflow, Google is aiming to make its ecosystem more self-contained and competitive for enterprise productivity.
Analysts expect the move to accelerate adoption among Workspace users who rely on Gemini for daily tasks, giving them an AI tool that blends external information with company context. The feature also signals Google’s ongoing shift from static chatbot assistance toward fully embedded, personalized AI research systems within its productivity suite.
Data Source
November 4, 2025
Anthropic
Claude Code
Anthropic adds code execution to MCP for faster, cheaper AI agents
Anthropic has expanded the Model Context Protocol (MCP) with built-in code execution, allowing AI agents to run logic and tool operations as code instead of direct model calls. The change significantly reduces token usage, latency, and costs for multi-tool workflows and makes MCP-based systems easier to scale across large ecosystems.
Anthropic’s Model Context Protocol, launched in late 2024, has become a widely adopted standard for connecting AI agents to external systems and tools. As developers began linking thousands of MCP servers, the cost of loading tool definitions and passing results through the model’s context window grew rapidly. Each tool call consumed additional tokens, inflating both response times and compute costs.
The company’s new approach addresses these limits by letting agents generate and execute code that interacts with MCP servers directly. Rather than loading every tool definition into the context, agents can now load only the functions required for a given task, run them in a sandboxed execution environment, and pass back concise outputs. Anthropic reported that this method can reduce token usage from 150,000 to 2,000 tokens in typical multi-tool chains—a 98.7 percent improvement.
By treating MCP servers as code APIs, agents can now filter or transform large datasets before results reach the model, perform conditional logic, and manage loops or retries inside the execution environment. This improves efficiency for complex workflows such as CRM updates, document processing, or multi-system synchronization.
Code execution also enhances privacy and state management. Intermediate data remains within the execution environment unless explicitly returned, and sensitive information such as emails or phone numbers can be tokenized before reaching the model. Agents can persist data and code modules as reusable “skills,” enabling faster task reuse and long-term state tracking across sessions.
Anthropic cautions that the approach requires secure sandboxing and resource monitoring, since executing model-generated code introduces new infrastructure demands. Still, for developers building large-scale or enterprise-grade agents, code execution with MCP represents a major step toward more efficient, cost-controlled, and composable AI systems.
Data Source
October 30, 2025
OpenAI
GPT
OpenAI launches Aardvark, an autonomous AI security researcher
Aardvark enters private beta as an agentic system built on GPT-5 that autonomously discovers, validates, and patches software vulnerabilities across modern codebases.
OpenAI has introduced Aardvark, an AI agent designed to act as an autonomous security researcher. Powered by GPT-5, Aardvark continuously scans source code repositories to identify, validate, and help fix vulnerabilities. The system is now in private beta and aims to address the increasing scale and complexity of software security challenges across enterprise and open-source environments.
Unlike traditional methods such as fuzzing or software composition analysis, Aardvark uses large language model reasoning and tool-based exploration to read, analyze, and test code as a human security expert would. It monitors commits and repository changes, detects potential exploits, validates them in sandboxed environments, and generates targeted patches using OpenAI Codex. Each proposed fix is reviewed by humans before integration through standard GitHub workflows.
OpenAI reports that Aardvark identified 92% of known and synthetic vulnerabilities during benchmark testing. In internal deployments, the agent has surfaced complex issues within OpenAI’s own systems and those of external partners. Beyond security vulnerabilities, Aardvark has also detected logic and privacy flaws, highlighting its potential for broader software quality assurance.
As part of its open-source commitment, OpenAI disclosed that Aardvark has found and responsibly reported multiple vulnerabilities in public projects, ten of which have been assigned official CVE identifiers. The company plans to provide free scanning to select non-commercial open-source repositories and has updated its coordinated disclosure policy to prioritize collaboration over rigid timelines.
With software underpinning nearly every industry and over 40,000 CVEs reported in 2024 alone, OpenAI positions Aardvark as a defender-first model that strengthens code security without slowing development. The company is inviting select organizations to join the private beta to further refine the system’s accuracy, validation, and usability before wider release.
Data Source
October 21, 2025
OpenAI
ChatGPT Atlas
OpenAI launches ChatGPT Atlas, a browser with ChatGPT built in
OpenAI has released ChatGPT Atlas, a new web browser that integrates ChatGPT directly into the browsing experience. The launch marks a significant move toward AI-driven web use, where users can interact with and delegate tasks to ChatGPT across any website without leaving the page.

OpenAI announced today that ChatGPT Atlas is available worldwide on macOS for Free, Plus, Pro, and Go users, with beta access for Business and Enterprise accounts. Versions for Windows, iOS, and Android are planned. The browser places ChatGPT at the center of user workflows, enabling instant assistance, automation, and personalized recommendations based on browsing context.
Atlas introduces browser memories, an opt-in feature allowing ChatGPT to remember context from previously visited sites. Users can manage or delete these memories at any time, ensuring full control over what the assistant retains. By default, browsing content is not used to train OpenAI’s models unless users explicitly enable data sharing.
Agent mode is now integrated directly into the browser, allowing ChatGPT to perform actions such as researching, booking appointments, compiling summaries, or making online purchases. The feature, available in preview for Plus, Pro, and Business users, executes actions within the browsing window and includes safeguards to prevent unauthorized operations or access to sensitive data.

OpenAI emphasized safety and transparency in the rollout. Atlas prevents agents from executing code, downloading files, or accessing other desktop apps. Sensitive sites such as financial platforms trigger additional confirmation steps. Parental controls from ChatGPT carry over to Atlas, with options to disable agent mode and browser memories for minors.
The launch positions OpenAI at the forefront of the shift toward “agentic” browsing — where AI assistants manage complex web interactions on behalf of users. Upcoming features include multi-profile support, improved developer tools, and ways for apps built with the ChatGPT Apps SDK to integrate more tightly with Atlas.
OpenAI’s ChatGPT Atlas isn’t just another browser launch. It’s a declaration of war over who controls the interface to the internet. The browser has always been the front door to the web, but OpenAI wants that door to open straight into ChatGPT’s world. This move isn’t about faster pages or prettier tabs. It’s about deciding who mediates your digital life: the browser, the search engine, or the AI that sits in between.
The timing is strategic. OpenAI has watched Perplexity’s Comet and the Dia Browser experiment with AI-native browsing, where assistants read and act directly on the web. Those projects showed the potential of an intelligent browsing layer. Atlas arrives with something they lack: hundreds of millions of active users already trained to ask ChatGPT for help. By embedding that behavior into a browser, OpenAI is turning familiarity into market power.
For Perplexity, Atlas is both validation and threat. Comet built its identity around answer-first search. Atlas goes further, converting search into direct action. Instead of fetching links, it plans, executes, and follows through. The challenge for OpenAI will be trust. Mistakes in search are annoying. Mistakes in automation are costly, and users will notice the difference.
Dia Browser, meanwhile, has leaned on privacy and local AI as its selling point. OpenAI is clearly preempting that line of attack with transparent data controls, optional memory, and clear consent flows. This is a philosophical divide: Dia argues that safety comes from staying local, while OpenAI bets on convenience guarded by user choice. Each approach reveals what they believe about how much control people really want.
If Atlas succeeds, it will redefine browsing from something users do to something done for them. That changes the web from a landscape of pages into a field of actions. Whoever owns the assistant that clicks, remembers, and decides on your behalf will shape what the internet feels like. Google knows it. Perplexity knows it. OpenAI just stepped into their front yard and started building.
Data Source
October 1, 2025
OpenAI
Sora
AWS
OpenAI launches Sora 2 and introduces social video app
OpenAI has released Sora 2, a new version of its AI video generation model, alongside the debut of the Sora app. The app positions OpenAI as both a model developer and a social platform operator. With higher realism, synchronized audio, and a distinct approach to feeds and responsibility, the launch marks a direct entry into competition with TikTok and Instagram.

OpenAI announced Sora 2 as a major advance in AI video generation. The model adds synchronized dialogue and sound effects, more accurate physics, and greater visual fidelity. Users can generate clips that extend to 10 seconds and include more complex interactions. OpenAI also introduced “cameos,” a feature that allows users to insert their own likeness or digital character into videos, enabling remix and collaboration within the app.
The Sora app is designed as the distribution layer for these capabilities. Users can create, share, and remix short AI videos directly within the platform. The interface resembles mainstream social video apps but integrates AI generation at its core. This places OpenAI in a new strategic position, not only as a research company but also as a consumer-facing platform.

OpenAI framed its approach with a public “feed philosophy” document. The company described a system that seeks to prioritize creativity and originality rather than maximizing engagement metrics. The feed is designed to reduce algorithmic amplification of viral trends and instead highlight diverse, authentic content. OpenAI also stated it will provide users with greater control over their own feed compared with incumbent social apps.
The responsibility strategy is central to the launch. OpenAI published a system card and safety framework outlining known risks such as misinformation, impersonation, and harmful content. Mitigations include watermarks, metadata tagging, parental controls, and staged rollout by geography. OpenAI said it is monitoring outputs closely to prevent the model from generating unsafe or misleading material, with additional safeguards for younger users.
The entry into consumer platforms has business implications. By launching Sora as an app, OpenAI is no longer solely a provider of foundational models to partners. It is competing directly with TikTok and Instagram, offering users an alternative space for short-form video that is AI-native from the start. This move could reshape how AI content enters mainstream culture, testing whether audiences prefer synthetic video as a primary format.
OpenAI’s dual emphasis on responsibility and creative philosophy sets it apart from existing platforms. TikTok and Instagram are optimized for scale and engagement, often criticized for their effects on attention and information quality. OpenAI is positioning Sora differently, betting that a curated, safety-forward environment will attract both creators and viewers. The strategy will determine whether Sora can grow into a viable social ecosystem or remain a niche showcase for AI video generation.
OpenAI may have just built the Vine of the AI era. Years ago, Elon Musk was loudly demanding someone bring back Vine. He even told his own teams to do it. They never did. OpenAI just quietly did. But instead of looping six-second jokes, Sora 2 produces ten-second films with dialogue, physics, and the polish of a professional studio.
The comparison with xAI’s Grok Video is unavoidable. Grok leans into anime tropes and adolescent fantasy. It looks like it was trained for manga enthusiasts and the men who buy body pillows. Sora, in contrast, is built for the mainstream. It comes with safety systems, labeling, parental controls, and a feed philosophy that sounds like a manifesto against the viral junk economy.
This is the bigger story. OpenAI is not just upgrading a model. It is trying to build a social platform with rules, structure, and taste. If it works, Sora will not be remembered as a toy. It will be remembered as the first professional-grade social app powered end-to-end by AI video. And yes, Elon, this one actually ships.
Data Source
September 29, 2025
OpenAI
ChatGPT
OpenAI Brings Instant Checkout to ChatGPT With Etsy and Shopify
OpenAI has launched Instant Checkout inside ChatGPT, starting with Etsy sellers in the U.S. and expanding soon to Shopify’s one million merchants. The system runs on the new Agentic Commerce Protocol, an open standard built with Stripe. This move positions ChatGPT not just as a conversational tool but as a direct commerce channel, changing how consumers buy online.

OpenAI announced that users in the U.S. can now buy products directly within ChatGPT through Instant Checkout. The feature is debuting with Etsy sellers and will expand to Shopify merchants, including larger brands, in the coming months. Purchases happen in-chat, with secure payments handled via Stripe, while merchants remain responsible for order fulfillment and customer relationships.
The checkout system is powered by the Agentic Commerce Protocol, an open-source standard co-developed with Stripe. It allows AI agents to initiate transactions while ensuring transparency and security. OpenAI emphasized that merchants keep control of customer engagement, paying only a small fee per transaction, similar to existing e-commerce platform rates.
For users, the feature eliminates redirections to external websites and enables one-click purchasing directly inside conversations. Planned expansions include multi-item carts, international rollout, and wider merchant participation.
The shift signals a broader trend of AI platforms entering retail. By embedding payments and commerce into natural-language chat, OpenAI is positioning ChatGPT as a transactional layer between consumers and businesses. This development could reshape customer acquisition strategies for online retailers and intensify competition in digital shopping channels.
Data Source
September 29, 2025
Anthropic
Claude Code
Anthropic expands Claude Code with autonomous workflows and VS Code integration
Anthropic has rolled out significant updates to Claude Code, its AI coding assistant. The release introduces a VS Code extension, an updated terminal interface, checkpointing for safer autonomous work, and support for customizable agent workflows. The tool now runs on Sonnet 4.5, enabling more complex development tasks for professional and enterprise teams.

Anthropic announced that Claude Code can now operate more autonomously within developer environments. A new VS Code extension brings native integration with one of the most widely used coding platforms. Alongside it, a redesigned terminal interface improves usability for direct command-line interactions. Both changes are intended to align Claude Code more closely with existing developer workflows.
The update also introduces checkpointing, allowing developers to rewind to earlier code states. This feature is designed to give teams more control and confidence when delegating complex tasks to the AI. By offering recovery points, checkpointing reduces risk in long-running or high-stakes projects.
Another key addition is the Claude Agent SDK. The SDK now supports subagents and hooks, which allow developers to extend and customize how Claude Code manages tasks. These features enable more specialized and automated workflows across different parts of a project.
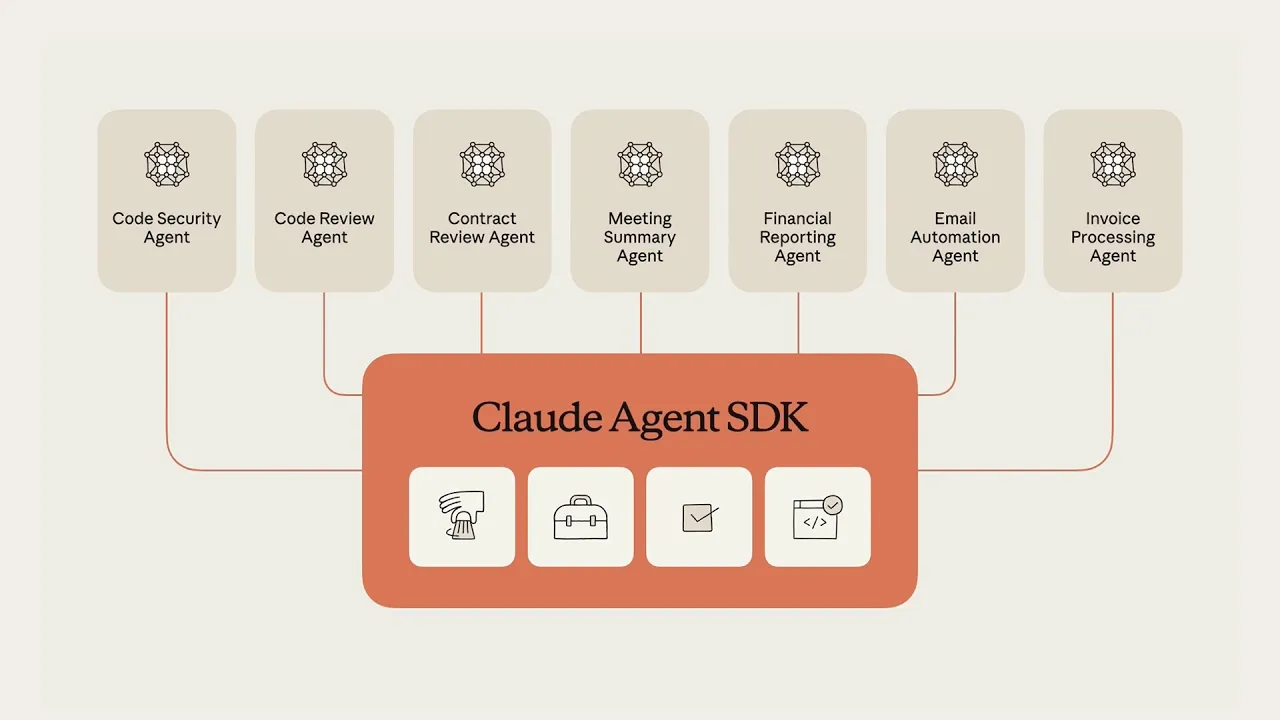
Claude Code now runs on Anthropic’s Sonnet 4.5 model. This upgrade supports longer and more detailed reasoning, making it possible for the system to handle extended development cycles and more complex codebases. Anthropic positions these updates as part of its strategy to make Claude Code a more autonomous, enterprise-ready AI development assistant.
Data Source
September 29, 2025
Anthropic
Claude
Anthropic releases Claude Sonnet 4.5 with new coding and reasoning capabilities
Anthropic has launched Claude Sonnet 4.5, its latest AI model designed to improve coding, reasoning, and computer-use tasks. The update introduces significant benchmark gains, new developer tools, and expanded integrations, while keeping pricing unchanged. The release signals Anthropic’s continued push to position Claude as a core tool for enterprise-grade AI workflows.

Claude Sonnet 4.5 is Anthropic’s most advanced coding and reasoning model to date. It leads on SWE-bench Verified for software engineering and achieved 61.4 percent on OSWorld, up from 42.2 percent with Sonnet 4. The model also shows improvements on GPQA Diamond, a graduate-level science reasoning benchmark, reinforcing its use in technical and research-intensive fields.
The release brings new capabilities for developers. Code checkpoints allow users to save and revert progress during long coding sessions. A refreshed terminal and a native VS Code extension simplify workflows. Long-memory tools now enable context editing, allowing users to maintain and manage complex projects over time.
Beyond coding, Claude apps now support code execution, file creation, and a Chrome extension for Max users. Anthropic also introduced the Claude Agent SDK, which gives developers access to the same infrastructure that powers Claude Code, enabling them to build agentic systems for enterprise automation.

Pricing remains the same as Sonnet 4 at three dollars per million input tokens and fifteen dollars per million output tokens. Anthropic emphasized that this consistency is intended to encourage broader adoption across enterprise teams and professionals in finance, law, medicine, and STEM.
Data Source
September 25, 2025
OpenAI
ChatGPT
OpenAI debuts ChatGPT Pulse for proactive daily updates
OpenAI has introduced ChatGPT Pulse, a new feature that delivers proactive, personalized updates. Initially available in preview for Pro users on mobile, Pulse shifts ChatGPT from reactive answers to daily insights based on memory, chat history, and optional integrations. The rollout positions ChatGPT as a more active assistant in planning and decision-making.

OpenAI launched ChatGPT Pulse to give users a curated stream of daily insights. Instead of waiting for prompts, Pulse generates one set of updates each day in the form of visual cards. These cards can highlight tasks, surface recommendations, or provide contextual follow-ups drawn from previous conversations, user memory, and connected apps.
The company is positioning Pulse as an evolution of its assistant model. Early features include integration with Gmail and Google Calendar, enabling updates on schedules, emails, and tasks. Users can guide Pulse by curating the cards and giving direct feedback, which helps the system refine its future updates. OpenAI says these controls will ensure users maintain oversight of what the assistant prioritizes.
The preview is limited to Pro subscribers on mobile, with plans to expand to Plus users and eventually the broader ChatGPT base. OpenAI emphasized that Pulse updates are proactive but constrained to once per day, aiming to balance usefulness with non-intrusiveness.
This launch signals OpenAI’s move toward embedding its assistant more deeply in daily routines. By combining memory, integrations, and curated feedback, Pulse could mark the transition of ChatGPT into a proactive productivity and learning tool rather than a reactive chatbot.
Data Source
September 18, 2025
Notion
Notion adds AI Agent in version 3.0 rollout
Notion has released version 3.0, introducing a built-in AI Agent that executes autonomous tasks across the platform and beyond. The Agent can search connected apps, manage Notion workspaces, and run operations for up to 20 minutes. The update positions Notion as a direct competitor to AI-first workplace tools by moving from note-taking toward task execution.
Notion 3.0 centers on its new AI Agent, designed to handle work inside and outside of Notion. The Agent can create databases, organize documents, and process requests that touch multiple pages at once. It also connects to external services, searching Slack, email, and the web to gather and synthesize information.
Each Agent is equipped with memory and can be configured with multiple profiles, enabling different roles for different workflows. Notion plans to expand customization further, letting users design Agents with specialized capabilities. The system runs autonomously for up to 20 minutes, giving it the ability to manage complex, multi-step tasks.

Examples highlighted by the company include turning meeting notes into full proposals, compiling user feedback from multiple channels, and drafting email campaigns directly inside the workspace. By embedding this functionality, Notion shifts closer to the emerging category of AI workplace assistants that combine productivity platforms with autonomous task execution.

The move signals Notion’s intent to extend beyond being a collaboration tool into a broader productivity operating system. For teams and enterprises already using Notion as a central workspace, the AI Agent reduces the need for context switching between apps and offers a competitive answer to specialized AI productivity platforms.
Data Source
September 15, 2025
Anthropic
Anthropic expands Claude usage index with global and US state data
Anthropic has published an update to its Economic Index, tracking how Claude is used across countries and US states. The report shows strong links between income and AI adoption, with automation use now exceeding augmentation overall. Business users on the API differ from consumer users in how they apply the model, underscoring divergent workflows across geographies and sectors.

Anthropic’s new report extends its Claude Economic Index to geographic data, mapping adoption by country and state. The United States records the highest overall usage, followed by India, Brazil, Japan and South Korea. Adjusted for working-age population, Israel, Singapore, Australia, New Zealand and South Korea rank at the top of the Anthropic AI Usage Index.
The analysis finds a close relationship between income and AI use. A 1 percent rise in GDP per capita is associated with a 0.7 percent increase in the adoption index globally. Within the United States, higher state-level GDP per capita predicts higher Claude usage, with the District of Columbia recording the strongest index. State-specific usage patterns also reflect local economies, with California skewed toward coding tasks, New York toward finance, and Hawaii toward tourism.
The distribution of task categories is shifting. Computer and mathematical work remains dominant but has declined slightly in share. Education and science tasks are rising steadily, while business, management and financial tasks have decreased.
The study also shows a shift toward automation. Directive conversations, requiring minimal user input, now account for a larger share of Claude usage. Automation has overtaken augmentation overall, with more than 49 percent of interactions automated. However, higher usage regions are more likely to rely on augmented workflows, while automation dominates in lower adoption areas.
Differences between consumer and business users are also pronounced. API users, typically businesses, lean heavily on automation, especially for coding and administrative tasks. Consumer users on Claude.ai show more collaborative patterns, with stronger emphasis on learning and iterative problem-solving.
Data Source
September 14, 2025
Thinking Machines
Enterprises Confront LLM Reliability, Determinism, and ROI Failures
OpenAI urges uncertainty-aware evaluation to reduce hallucinations, Thinking Machines outlines reproducibility fixes, and MIT reports 95 percent of enterprise GenAI pilots fail to deliver measurable ROI. The findings highlight a widening gap between model capability and business outcomes.
Where are NOT there yet!
Large language model deployment is colliding with structural limits in evaluation, inference reliability, and enterprise integration. OpenAI has published an explainer arguing that benchmarks optimized solely for accuracy push models to guess, which sustains hallucinations. The company proposes new tests that penalize confident errors and reward abstention, shifting incentives toward calibrated uncertainty.
Parallel to evaluation, reliability at the inference layer is under scrutiny. Thinking Machines Lab has shown that even with temperature set to zero, LLMs can return different outputs due to batch-size–dependent GPU kernels and lack of batch invariance in inference servers. The lab proposes batch-invariant serving, deterministic kernel selection, and rigorous reproducibility tests as requirements for enterprise-ready systems.
On the business side, MIT Project NANDA reports that 95 percent of corporate generative AI pilots are failing to deliver measurable ROI. The report finds only 5 percent of pilots reach production scale. Failures are less about model quality than about workflow learning and integration. Enterprises that partnered with external vendors or adapted systems to process-specific contexts were more likely to deploy successfully. Internal-only builds lagged.
The report also highlights spending patterns that skew toward front-office pilots such as customer chat assistants while underinvesting in back-office automations. The latter offer clearer savings but receive limited funding. Shadow AI adoption is spreading as employees adopt personal tools when sanctioned deployments stall, underscoring demand for flexible systems even as official projects stagnate.
For enterprises, the combined findings present a sharper playbook. Technical leaders must adopt uncertainty-aware benchmarks and enforce reproducibility standards in inference. Procurement and finance teams must prioritize outcome-based vendor contracts, invest in integration rather than model experimentation, and measure pilots against cost and revenue metrics. The industry’s pivot from model hype to operating discipline is becoming unavoidable.
Data Source
September 11, 2025
Anthropic
Claude
Anthropic adds memory features to Claude for team and enterprise users
Anthropic has introduced memory capabilities in its Claude app for Team and Enterprise plans. The update enables Claude to retain project context, preferences, and past conversations across sessions. The company is also launching project-based memories, incognito chats, and admin controls to balance continuity with privacy.

Anthropic announced that memory is now available in the Claude app for organizations on Team and Enterprise plans. Users can enable the feature in settings and review or edit what the model remembers through a memory summary page. This gives teams visibility into stored information and control over updates or deletions.
The update introduces project-based memories, creating separate memory spaces for different initiatives. This structure helps avoid context overlap between client work, product launches, or internal projects. By carrying forward only relevant history, the feature is designed to reduce repetitive explanations and accelerate collaboration.
Anthropic is also adding an incognito chat mode. Conversations in this mode are excluded from both chat history and memory. The feature is available to all Claude users, including those on the free plan, and is intended for sensitive or one-off interactions.
For enterprise customers, memory is optional. Administrators can disable the feature across their organization, while individual users retain granular controls to manage what is remembered. This approach is aimed at balancing efficiency gains with privacy and governance requirements.
The launch positions Claude more competitively among workplace AI assistants. Memory features have become a key differentiator in enterprise adoption, where continuity, transparency, and data control are central to AI integration.
Data Source
September 10, 2025
OpenAI
ChatGPT
OpenAI adds Developer mode to ChatGPT with full MCP client support
OpenAI has introduced a new Developer mode for ChatGPT, giving Pro and Plus users full access to Model Context Protocol (MCP) connectors. The beta feature allows both read and write actions across custom tools, making ChatGPT a central hub for external integrations. While it expands automation options, the mode requires careful handling due to the risk of data loss or misuse from incorrect tool calls.
OpenAI’s Developer mode is now available to Pro and Plus subscribers on the web. Once enabled through the Connectors menu in settings, it provides a dedicated interface for connecting to remote MCP servers. Supported protocols include server-sent events and streaming HTTP, with OAuth or no authentication available.
Users can add, toggle, and refresh tools exposed by MCP servers directly inside ChatGPT. During conversations, Developer mode appears as an option in the Plus menu. To ensure correct tool usage, users are advised to issue explicit instructions, disallow alternatives, and disambiguate overlapping tool names. OpenAI recommends structuring prompts to specify input formats and call order, particularly when chaining read and write operations.
Write actions require explicit confirmation before execution. ChatGPT displays the full JSON payload of each tool call, allowing users to review parameters and outputs before approval. The system recognizes the readOnlyHint annotation to distinguish safe read operations from potentially destructive actions. Users can choose to remember tool approvals within a single conversation, though new or refreshed chats reset confirmation requirements.
We’ve (finally) added full support for MCP tools in ChatGPT.
In developer mode, developers can create connectors and use them in chat for write actions (not just search/fetch). Update Jira tickets, trigger Zapier workflows, or combine connectors for complex automations. pic.twitter.com/1W0rTGGEnu— OpenAI Developers (@OpenAIDevs) September 10, 2025
By exposing the full MCP interface, Developer mode allows ChatGPT to act as a client for enterprise systems, CRMs, code repositories, and other external applications. This expands the platform’s role in workflow automation but also raises safety concerns. OpenAI cautions developers to monitor for prompt injection risks, incorrect tool behavior, and malicious connectors.
Data Source
September 9, 2025
Anthropic
Claude
Anthropic adds file creation and editing to Claude
Claude can now generate and edit Word, Excel, PowerPoint, and PDF files. The new feature runs in a sandboxed environment with code execution and limited internet access. It targets productivity workflows for paid users and positions Claude more directly against ChatGPT and Microsoft Copilot.

Anthropic has introduced a new file creation and editing capability for Claude. The feature allows the AI assistant to produce and modify Word documents, Excel spreadsheets, PowerPoint slide decks, and PDFs. It also supports file uploads, letting users transform data from formats such as CSV or PDF into new documents.
The capability runs inside a sandboxed environment that permits code execution and limited internet access. Within the sandbox Claude can fetch dependencies, manipulate data, and generate charts or formulas. Anthropic notes that the environment is restricted but still advises users to monitor outputs closely. Risks include errors in data handling, malformed files, or exposure to potentially unsafe external code.
The update is available for Max, Team, and Enterprise users. Free and entry-level paid users do not currently have access. This tiered availability aligns with Anthropic’s focus on professional and business customers who require advanced document automation.
By automating workflows such as converting reports, generating financial models, and producing presentations, the feature reduces manual work for analysts, marketers, and teams managing recurring document tasks. It also brings Claude closer to competing products like ChatGPT with Code Interpreter and Microsoft Copilot, which already provide similar functionality.
The launch raises expectations for AI assistants to move beyond conversation and into structured document production. It could accelerate adoption in enterprise settings, where productivity gains are weighed against governance and security considerations.
Data Source