Microsoft releases VibeVoice-1.5B open-source long-form TTS model
Microsoft has released VibeVoice-1.5B, an open-source text-to-speech model capable of generating up to 90 minutes of continuous audio. The model can synthesize expressive conversations with up to four distinct speakers and is available under the MIT license with safeguards for responsible use.
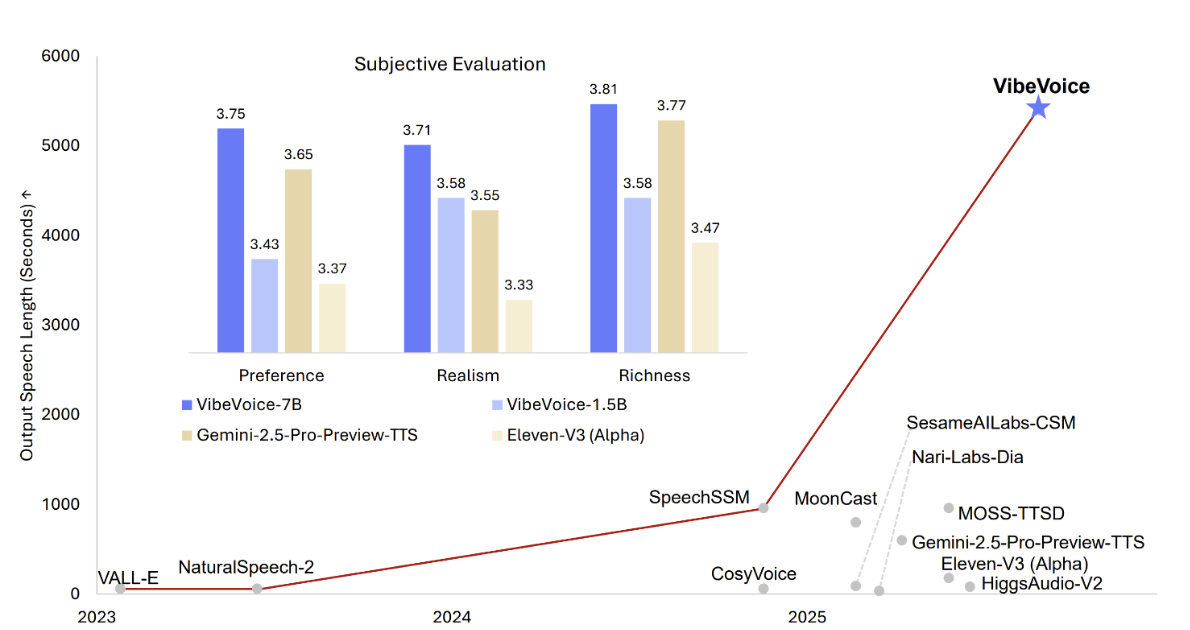

Microsoft’s new release, VibeVoice-1.5B, introduces long-form text-to-speech generation with multi-speaker support. The model can generate expressive dialogue involving multiple speakers, making it suitable for podcasts, audiobooks, and simulated conversations. Microsoft designed it to handle up to 90 minutes of uninterrupted speech, a benchmark that expands potential use cases for synthetic audio content.
The model is built on a 1.5-billion-parameter Qwen2.5-1.5B backbone and uses continuous speech tokenizers operating at 7.5 Hz. It employs a next-token diffusion framework that enables smooth and natural speech generation across extended durations.
To mitigate misuse, VibeVoice-1.5B integrates watermarking and audible disclaimers into generated audio. Microsoft released the model under the MIT license for research use, which allows broad experimentation while maintaining safeguards. The release includes documentation and examples that highlight applications in conversational AI and content production.
Alongside the release, Microsoft previewed a larger VibeVoice-7B model. Early benchmarks suggest that the 7B version delivers higher speech quality and more natural prosody compared to the 1.5B model. However, the trade-off is shorter output duration, with conversations limited relative to the extended 90-minute capability of the smaller model. This signals a possible product tiering where developers may choose between long-form generation at scale or higher-fidelity synthesis for shorter audio tasks.
VibeVoice-1.5B will be relevant to developers, AI audio researchers, and builders of no-code TTS applications. By making long-form, multi-speaker synthesis accessible in an open-source format, Microsoft positions the model as both a research tool and a foundation for applied audio workflows.
Pure Neo Signal:
We love
and you too
If you like what we do, please share it on your social media and feel free to buy us a coffee.

